YouTube And Alibaba Stepping Up In "The Great Data Race"
Artificial intelligence is creating new relationships. It is also bringing on a new focus.
While data was always important, it is getting crucial.
'Data is the new oil".
While this is not exact, it is good enough as a mental framework. Clive Humby, a British mathematician and data scientist, is credited with coining the phrase in 2006.
Here is the basis behind the analogy according to Groq:
This is something that has only grown.
We are now seeing YouTube and Alibaba stepping up their games.
The Great Data Race
There is a race for more data. Companies are building out features in an effort to collect more.
In this article we will cover two examples where the Great Data Race is taking another step forward.
We know Google is generating a huge amount of data from YouTube. This is no sufficient.
Before getting into the details, I want to, once again, state my theory about social media and data. Social Media features are now being designed to generate more data. That is it.
With Google, the goal is to start pulling away from Discord.
We know the latter is a treasure trove. This application has long been popular with gamers. Google is looking to cut into that.
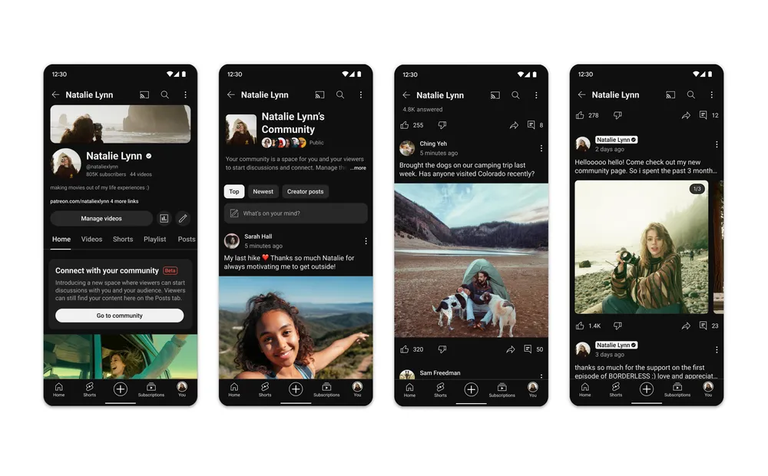
It released a communities feature that will allow content creators to engage with their audience in a more direct manner.
At its Made On YouTube event on Wednesday, the company announced a new dedicated space for creators to interact with their fans and viewers. The space, called “Communities,” is kind of like a Discord server built into a creator’s channel. With Communities, YouTube is hoping creators won’t need to use other platforms like Discord or Reddit in order to interact with viewers.
Notice the last sentence.
Another way of phrasing this is YouTube is hoping to pull the data that content creators are presently giving to platforms like YouTube and Discord.
With more than 1 billion users each month, if even a fraction utilize this feature, it could be a major boom for Google's data collection.
After all, Gemini is a hungry beast.

Alibaba Open source Tools
The Chinese are not in idle mode. They are pushing ahead, looking to replicate things on their side of the world.
Alibaba just released a bunch of open source models that is incorporated into its cloud service. The goal should be clear:
Alibaba is hoping its latest AI offerings may tempt customers around the world to sign up to its cloud services.
Another way of reading this is to gather more data. If companies globally flock to Alibaba's cloud service, they will be feeding the tech giant with even greater amounts of data.
The same is the game everywhere we look.
Of course, we start to see the feedback loop right before our eyes. The models that it is offering were trained on data Alibaba accumulated. To keep the process moving, it requires more data to feed in.
Here we see new features brought out to generate data. The next generation of rollouts will likely mirror this. New features can entice users to engage with the servers with more frequency, adding to the accumulation the company experience.
It is the Great Data Race.
The Role Of Web 3.0
By now it should be clear what anyone who is involved in technology is doing. Everyone seeks to generate more oil for themselves.
Of course, there is a positive to this. The amount that can be generated is near limitless. Each day we create more, at a growing pace. While the hunger of these models might be outpacing what humans can create, it is still a large amount.
The question always comes back to where is the data going?
These two examples are more of the same. Every single token people create using these services (applications) only feeds the centralized entities known as Big Tech.
Nothing being described here is available to humanity.
Web 3.0 is a different animal. A conversation such as the Discord type service being offered by YouTube could well be housed on a public blockchain. While there might be private messaging, most of those "rooms" are public.
It all starts with the data.
ChatGPT, according to many, is the leader in the LLM field. This was a company that started in 2015 yet did not openly released a product for a number of years. Why is that?
The starting point for that company was to amass data. There is no way to create a chatbot without it. The company did not start with a decade of data like many other entities.
Web 3.0 is no different. We see that Web 2.0 is starting to lock down. Naturally, as they add more, this is only going to increase the amount that other entities do not have access to.
It is time to start talking about this. Most are oblivious to what is taking place. They realize data is being used to generate products that will likely result in tens of billions in revenues.
Yet they keep feeding the centralized beasts.
We can expect these companies to keep rolling out features that generate more data. They understand the data feedback loop very well.
It is something the masses in Web 3.0 best learn.
Posted Using InLeo Alpha
🎉 Upvoted 🎉
👏 Keep Up the good work on Hive ♦️ 👏
❤️ @mysteriousroad suggested sagarkothari88 to upvote your post ❤️
looks like that all the medias want to be a social media too to keep the user all the maximun time in the app, it is awful see my mother watching youtube videos all the time
https://inleo.io/threads/view/omarrojas/re-leothreads-2pc23chfy?referral=omarrojas
It's very heart warming that we in Web 3.0 are very much ahead of many others trying to find their ways up there.
We will keep moving ahead of them all. Thank you for sharing.
As someone who creates on YouTube, the new content features are a big step in the right direction but I agree with your overall assessment about data collection starting to centralize. It's a trade off and until we have a viable web3 alternative people will continue to flock to these platforms.
If data is the new oil, shouldn't every data-producing person (or entity) be like an oil-producing state?