The Fear We Will Run Out Of Data
Artificial intelligence is a hungry beast, specifically when training large language models (LLM). This is something that many are debating.
The training of Llama3 used 16 trillion tokens. Meta will have a cluster of more than 100K GPUs, presumably used to train future models. Jensen Huang, the CEO of NVIDIA, was asked if we are in the era of 200K and 300K clusters, and he responded to the affirmative.
As these clusters get larger, more data is required. Much was made of companies scarping the Internet. At the same time, many countered this by blocking robot.txt. Then we have platforms like X which are now using all the data to train.
The great data rush is on.
So what is the situation and how does Web 3.0 play into this?
That is what we look at.
The Fear Data Will Run Out
Is this a valid concern?
Whatever side of the debate we look at, it is clear there are very intelligent people taking up both positions. Because of this, I think discounting either is a major risk.
Certainly, there is the potentiality that data could run out. By this, we are referring to human generated. The ability to generate synthetic data is only growing.
And here we encounter our first challenge.
This is a useless debate if synthetic data proves to be valid for training future models. It is something else that is hotly contested. Many feel that synthetic data degrades over time since it basically ends up in a feedback loop.
Again, we see highly knowledgeable and experienced people on both sides of the debate.
The reality is we have no idea how synthetic data will perform long term. We know the ability to generate is simple, and taking place before our eyes. Every prompt results in more being created.
Hence, we will focus our discussion upon human generated data.
So what is the answer?
Humans Creating More
The amount of data humans are generating is enormous. However, it is still trailing the consumption rates of these models.
Epochai estimated there are roughly 300 trillion tokens available from humans. If we look at what Meta did, we can see how 100 trillion token models are not that far off. In fact, I would not be surprised if that is what is required for Llama4 (definitely Llama5).
We estimate the stock of human-generated public text at around 300 trillion tokens. If trends continue, language models will fully utilize this stock between 2026 and 2032, or even earlier if intensely overtrained.
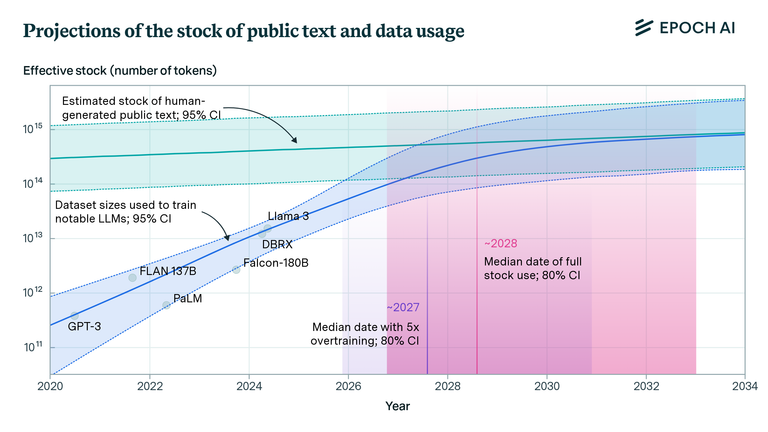
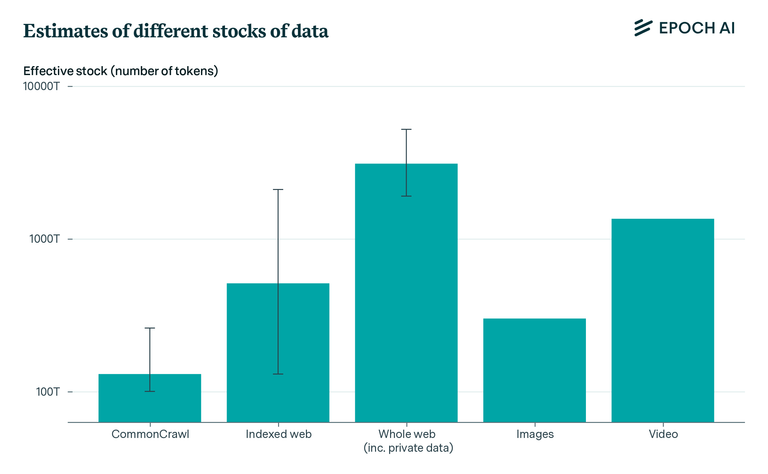
Here is a breakdown of what is estimates is available.
As stated, these numbers will skyrocket when computers generating data. We see the ability to produce at speeds incomprehensible to humans.
Consider the idea of generating a 2,500 word article. How long does that take a human? Contrast that with an application such as Claude3, which can output that in under 30 seconds.
So volume, if synthetic is valid, is not a concern. But is it useful over time? That is where we are at the crossroads.
For this reason, it is imperative that human data keep growing. Obviously, the industry will be adjusting algorithms to get better output with less data. At the same time, private data becomes available when individual entities with said data set up their own models. In this instance, it is not part of a LLM but a system that is used within a company.
We also have the advantage that multi-modal is becoming an option for more entities. As the price of compute drops, we see the ability to train on images and video increasing. This will help to alleviate some of the deficit due to the fact video generation is growing at an outsized pace.
Web 3.0: Part Of The Solution
This discussion focuses upon the amount of data. We have not dove into the accessibility of said data.
For example, we know much of the video content out there is controlled by Google through its YouTube platform. This data is not really available to anyone outside that company. That said, it doesn't mean that other Big Tech firms are not scraping there. However, that opens up a major can or worms.
We also have to keep in mind the size of companies. Google might not go after Meta since those two will be locked up in court forever. That said, if a smaller entity did the same thing, Google might go after them.
Here is where Web 3.0 enters.
The democratization of data is almost as important as the discussion around the total amount. If the likes of X, Google, and Meta are the only ones with access to what is required, the future Internet will be even more siloed than today.
Web 3.0, through the use of blockchain, alleviates this by offering a network where writing to the database is permissionless. This means any data provided is available for anyone to use.
Even if data is public, if nobody has access to it other than those companies that pay, we are basically looking at something that is non-existent.
It quickly becomes clear the role that Web 3.0 can play. To me, the main benefit is the democratization of data. This is the single most important issue with regards to freedom.
Unless developers can gain access to data for their system, we are dependent upon Big Tech. I think many will agree this is not a pleasant thought.
AI is a centralizing force. Blockchain is the counter to this. Even with synthetic data, we can see how important it is get it on open networks. OpenAi, Anthropic, and the others are not going to share the synthetic data either.
Ultimately, we are dealing with compounding. If there are more AI features tied to blockchain, the opportunity for more open data increases. When people use the different services, if the data is posted to chain, it expands what is available.
Thus, if synthetic data does prove to be viable for future models, the world has access to a lot more. We know the servers at Big Tech are seeing their synthetic data growing by huge amounts.
Posted Using InLeo Alpha
@tipu curate
Upvoted 👌 (Mana: 46/56) Liquid rewards.
Information only ever comes from a mind.
For now, the majority will continue feeding data into big tech, because it's easy to download their apps, and these companies already have the network effect.
But I think the trend of people switching over to web 3.0 will grow, especially when they realize they can receive rewards for their data (which will increase in value over time).
I like your point that Web3's role in data availability for training AIs is essential. It's a given that well-resourced interests will use all the data they can. If the little guy is to keep up, then improving the ratio of public to private datasets will matter.
Synthetic data has limits before error rates become a problem, but it has its uses. I worked on one image recognition project where we took the AI expert's request for 1200 training examples per item and reduced that to 7 by applying some domain-specific knowledge and my experience with image generation to produce synthetic data.
While synthetic data has its uses, my experience suggests it can't fully replace the need for diverse real-world data. Imagine exploring a landscape. Densely populated areas represent known information, while uncharted territories hold the potential for new discoveries. AI trained on a limited dataset might struggle to explore these uncharted territories, potentially limiting its expressiveness.
So, yes, web3 content production is crucial, not least so that the little guys have sufficient data to train on.